Does One Large Model Rule Them All?
Predictions on the Future AI Ecosystem
Maithra Raghu (Samaya AI), Matei Zaharia (Databricks), Eric Schmidt (Schmidt Futures)
The past 10 years have seen a constant stream of AI advances, with each new wave of developments enabling exciting new capabilities and applications. The biggest such wave has undoubtedly been the recent rise of a single, general AI model, for example LLMs, which can be used for an enormous diversity of tasks, from code generation, to image understanding to scientific reasoning.
These tasks are performed with such high fidelity that an entire new generation of technology applications is being defined and developed. While it’s thrilling to contemplate the potential impact, this runaway success does leave us with a deeply uncomfortable question about the future AI ecosystem:
Will the future AI landscape be dominated by a single general AI model?
Specifically, will the future AI landscape:
- Be dominated by a small (<5) number of entities, each with a large, general AI model?
- Have these general AI models be the critical component powering all significant technical AI advances and products?
With the release of models like ChatGPT and GPT-4 which have transformed our understanding on what AI can do, and the rising costs for developing such models, this has become a prevalent belief.
We believe the contrary!
- There will be many entities contributing to the advance of the AI ecosystem.
- And numerous, high-utility AI systems will emerge, distinct from (single) general AI models.
- These AI systems will be complex in structure, powered by multiple AI models, APIs, etc, and will spur new technical AI developments.
- Well defined, high-value workflows will primarily be addressed by specialized AI systems not general purpose AI models.
We can illustrate our prediction for the AI ecosystem with the following diagram:
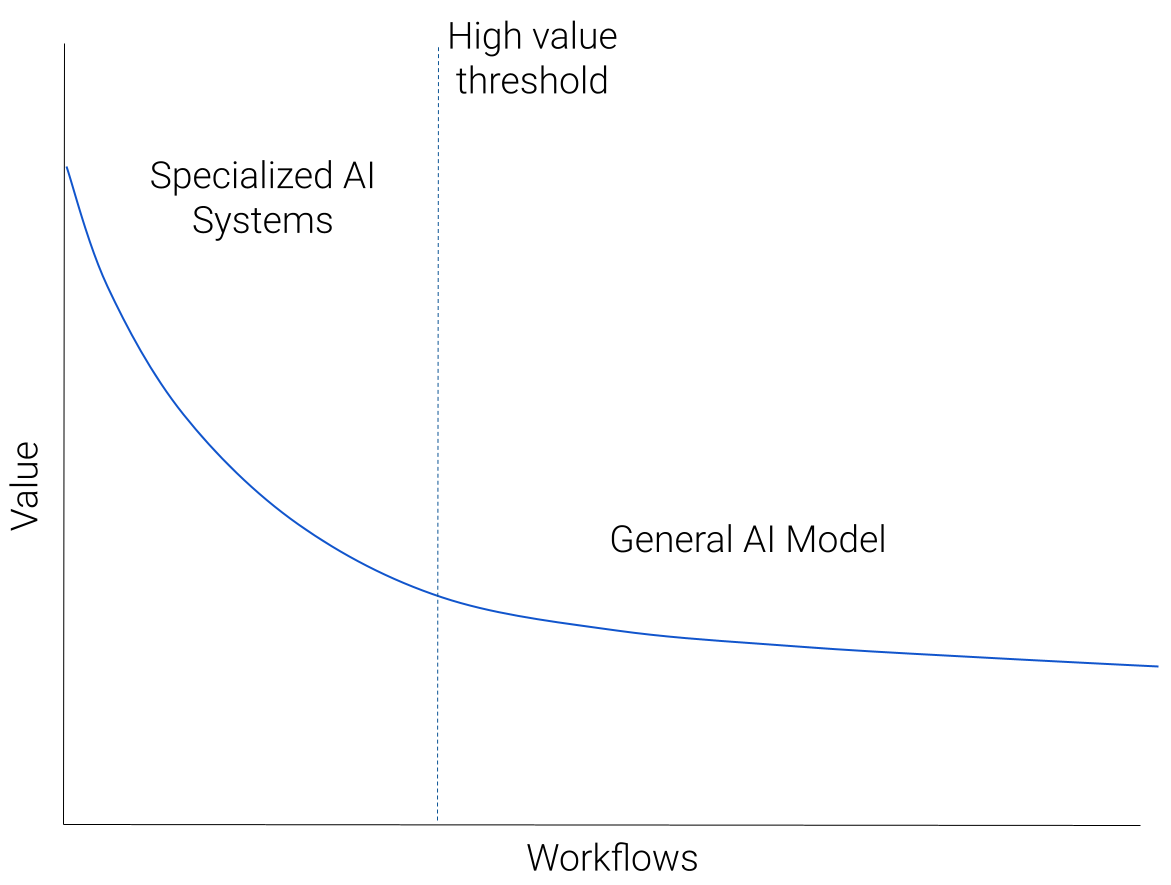
Imagine we took all workflows amenable to AI-based solutions, and plotted them in decreasing order of “value”. Value could be revenue potential, or simply utility to users. There would be a small number of very high value workflows — a large market or a large number of users with a clearly defined painpoint addressable by AI. This would descend to a long, heavy tail of diverse, but lower value workflows, representing the many custom predictive tasks that AI could help with.
What are examples of high value workflows? It’s still early, but we’re seeing exciting developments in coding assistants, visual content creation, search and writing assistants.
What about the heavy tail of lower value workflows? These will be less clearly specified, custom needs arising out of custom circumstances. For example, triaging requests from a customer support bot via classification.
We predict that the top left of the diagram (high value workflows) will be dominated by specialized AI systems, and as we follow the blue curve down to lower value workflows, general AI models will take over as the predominant approach.
At first, this picture looks counterintuitive. Some of the most advanced AI capabilities seem to be coming from general purpose models. So why shouldn’t those dominate the high value workflows? But thinking through how the ecosystem is likely to evolve, there are a number of important factors supporting the picture, which we expand on below.
Specialization is Crucial for Quality
High value workflows require high quality, and reward any quality improvements. Any AI solution applied to a high value workflow is constantly adapted to increase quality. As gaps in quality arise from workflow specific considerations, this adaptation results in specialization.
Specialization could be as straightforward as tuning on workflow specific data, or (more likely), developing multiple specialized AI components.
We can walk through a concrete example by considering current AI systems for self-driving cars. These systems have multiple AI components, from a planning component, to detection components and components for data labeling and generation. (See e.g. Tesla’s AI day presentations for more detail.)
Naively replacing this specialized AI system with a general AI model like GPT-4 would lead to a catastrophic drop in quality.
But could a more advanced general AI model, GPT-(4+n), applied strategically, perform this workflow?
We can conduct a thought-experiment for how this might unfold:
- Imagine GPT-(4+n) is released, with remarkably useful capabilities, including for self-driving.
- We can’t instantly replace the entire existing system.
- So we identify the most useful capabilities of GPT-(4+n) and look at adding those in as another component, perhaps via an API call.
- This new system is then tested out, and inevitably, gaps in quality are identified.
- There is a push to address these gaps, and as they arise from a specific workflow (self-driving), workflow specific solutions are developed.
- The end result could have the API call completely replaced with a new, specialized AI component, or augmented with other specialized components.
While this thought experiment might not be fully accurate, it illustrates how we may start with a general AI model, but then specialize it substantially to improve quality.
In summary, (1) quality matters for high value workflows, and (2) specialization helps with quality.
Making Use of User Feedback
Closely related to quality considerations is the role of user feedback. There is clear evidence that careful tuning on high quality, human “usage” data (e.g. preferences, instructions, prompts and responses, etc), is central in pushing the capabilities of general AI models.
For example in LLMs, techniques such as RLHF (Reinforcement Learning from Human Feedback) and supervised learning on human-like instruction/preference data have been crucial in getting high quality generations and instruction following behavior. This was notably demonstrated with InstructGPT and ChatGPT, and is now spurring a number of LLM development efforts (Alpaca, Dolly, gpt4all).
Similarly, we expect user feedback to play a key role in pushing capabilities of AI for specific workflows. But effectively incorporating that feedback will require having fine-grained control over the AI system. Not only might we want to carefully tune underlying models to the user feedback (hard with a general AI model due to cost and limited access), but we may need to adapt the structure of the entire AI system, e.g. define interactions between data, AI models and tools.
Setting up such fine-grained controls for a general AI model is challenging from engineering (diverse finetuning approaches, chaining API calls, working with different AI components), cost (large models are expensive to adapt) and security (parameter leakage, data sharing) perspectives.
In summary, the fine-grained control needed for user feedback is much easier to achieve with specialized AI systems.
Proprietary Data and Proprietary Knowledge
Many high-value, domain-specific workflows rely on rich, proprietary datasets. Optimal AI solutions for these workflows would require training on this data. However, the entities that own these datasets will be focused on preserving their data moat, and are unlikely to allow unfederated access to third parties for AI training. So these entities will build AI systems specialized for these workflows in-house or via specific partnerships. These will be distinct from general AI models.
Related to this, many domains also make use of proprietary knowledge — a “trade secret” only understood by a few human experts. For example, the technology powering cutting-edge chip fabrication at TSMC, or the quantitative algorithms used at a top hedge fund. AI solutions leveraging this proprietary knowledge will again be built in-house, specialized to these workflows.
These are examples of a “build vs buy” calculation that has occurred for many previous tech cycles and will recur in this wave also.
Commoditization of AI Models
Simultaneously with efforts to develop expensive, proprietary models like GPT-4, are efforts to build and release AI models such as Llama, which are then rapidly optimized to run even on a phone(!)
These are examples of a fierce, ongoing contest between (1) cost-based utility, and (2) efficiency.
Efficiency refers to the rapid process of making new AI advances less costly while maintaining utility. This happens due to a few key properties:
- The AI field has strong roots in collaborations, published research and open sourcing, resulting in speedy knowledge dissemination of (painstakingly discovered) technical insights.
- Compute costs for training popular AI models decrease quickly due to better hardware, infrastructure and training methodology.
- Efforts to collect, curate and open source datasets help democratize model building and improve quality.
For our current most powerful models, it seems likely that efficiency will win in the contest, leading to commoditization of these models.
The Future of General AI Models?
But does this mean all large, general AI models will be commoditized?
That depends on the other contestant, cost-based utility. If an AI model is useful but also very costly, it takes longer for the efficiency process to run its course — the more upfront cost, the longer it takes to reduce the cost.
- If the costs remain in the range of where they are today, there will likely be total commoditization.
- If costs increase by an order of magnitude but utility shows diminishing returns, then again we will see commoditization
- If costs increase by an order of magnitude and there are proportional gains in utility, then it’s likely that there will be a small number of very high cost, general purpose models that are not commoditized.
Which is most likely to happen?
It’s hard to predict for certain. Future AI models definitely have scope to be built with even larger amounts/types of data and increased compute. If the utility also continues to increase, we will have a few, expensive general AI models used for an enormous tail of diverse, hard-to-define workflows as illustrated in the diagram above — doing for AI what cloud did for compute.
In Conclusion
Despite the decade-long wave of AI advances, the future of AI still looks more eventful than the past! We expect a rich ecosystem to emerge, with a variety of high-value, specialized AI systems, powered by different AI components, along with a few general AI models, supporting a large diversity of AI workflows.